Open Source as a Complex Adaptive System
Moreno Muffatto
University of Padua, ITA
Matteo Faldani
University of Padua, ITA
Introduction
The concepts of complexity prevalent at various historical times have influenced the frames of mind with which organizations and the models of social planning and organizational design have been analyzed.
During the Industrial Revolution, the model of organizational design derived from the conceptual model of the machine. In this model, the concept of the hierarchical control of functions prevailed. The consequent approach was top-down thinking. Much of the organizational theory of the twentieth century was based on determinism, reductionism, and equilibrium as key principles. If an organization is conceived of as a machine, the control of the organization is obtained through a reduction in its complexity; that is, in the states of the machine or its variety.
The Information Revolution and the development of networks have produced phenomena such as the growing connection between elements that are often extremely different from one another (computers, people, even smart objects). This has led to phenomena that cannot be planned according to a top-down logic, but, on the contrary, “emerge” from interactions between elements and therefore “from the bottom.” The approach most suitable for analyzing these phenomena is bottom-up thinking.
If in the past the world could be represented as a machine, today it is represented as a network and increasingly as an ecosystem. The Internet, for example, can be considered not only as a technological infrastructure and a social practice, but also as a new way of thinking related to the concepts of freedom of access and diffusion of knowledge. Furthermore, the Internet is an organizational model without a center and without absolute control.
With the development of information networks, the Internet in particular, it has been observed that not all phenomena that are developed can be designed and planned. In other words, networks involve social structures that make phenomena, to a certain degree, “emergent.” Therefore, there has been growing interest in an approach that interprets phenomena from the bottom up; that is, from the network of relationships and the interactions between players.
The growth of the Internet has led to the development of many types of online communities whose aims vary significantly. Only the creation of the Open Source community has offered the possibility of developing something concrete; that is, software products. Software lends itself to online development since it can be easily transferred via the Internet itself. The many communities working together to produce Open Source software offer new stimuli for research in the context of complexity theory. The complexity of Open Source is due not only to technical aspects, relative to the complexity of software, but to the social complexity that characterizes the software development process.
In order to better understand this social complexity, some important studies have been carried out to interpret complex social phenomena (Axelrod & Cohen, 1999; Kauffman, 1995; McKelvey, 1999; Waldrop, 1992). In this analysis we will make reference to the theory of complex adaptive systems. A system can be considered complex and adaptive when the system's agents have the possibility of continually adapting their actions in response to the environment and the behavior of the other agents. Therefore, the agents have the ability to influence and be influenced by other agents. Consequently, the possibility of transferring information from one agent to another is extremely important in complex systems.
One of the most significant characteristics of complex systems is the presence of emergence; that is, the emergence of new states in the system that have new capabilities and offer new evolutionary possibilities. The very nature of this phenomenon makes it difficult to foresee what the new states of the system will be, since it is not always possible to extrapolate the new system properties from the existing system components.
The unpredictability of events and of the results makes understanding and interpreting a complex system that much more difficult. Nonetheless, one of the most interesting and significant aspects of the approach to complex systems is not the search for methods to limit their complexity, but, on the contrary, the exploitation of the complexity itself (Axelrod & Cohen, 1999).
The Open Source community and its activities can be considered to have the characteristics of a complex adaptive system. The Open Source system is unique because it is neither controlled by a central authority, which defines strategy and organization, nor totally chaotic. It can be placed in a middle position between a designed system and a chaotic one (Lerner & Tirole, 2001). In this position, nonformal rules exist that allow the system to produce appreciable results.
THE OPEN SOURCE COMMUNITY
Software has not always been a commercial product. It was originally considered to be simply a tool for using computer hardware. Only hardware had a commercial value, whereas software was a complementary product needed to use and diffuse computers. Consequently, software was produced and distributed freely, just like other products based on knowledge and scientific research. The development of software was the fruit of the work of a small community of university researchers who collaborated closely with a few hardware manufacturers. Software was considered, just as academic research is, to be a common good (Di Bona et al., 1999).
With the widespread diffusion of personal computers, software took on the characteristics of a commercial product. Since not all personal computer users had the technical skills to understand, develop, and configure software themselves, they were willing to buy it (Tzouris, 2002; Weber, 2000).
In 1985, Richard Stallman, a researcher at MIT, established the Free Software Foundation (FSF) with the aim of rebuilding a community for the free and independent development of software (Free Software Foundation, 2002). However, the word “free” was often wrongly interpreted as “free of charge.” Therefore, it became necessary to substitute the word “free” with another word that described the characteristics of product accessibility, efficiency, reliability, and flexibility.
In 1998, another group of developers founded the Open Source Initiative (OSI) with the aim of making the concept of free software appealing to companies as well (Open Source Initiative, 2002). The term “free software” was thus substituted with “Open Source.” In order to avoid further misinterpretations of the new term, an official definition was drawn up to specify the indispensable characteristics of Open Source products. For a product to be considered Open Source, it must respect a series of rules summarized in the license that accompanies the product's source code. These rules regard the copying and distribution of the software, including the source code, and the products derived from it. Open Source licenses guarantee the freedom to distribute and use the software, study the source codes, and, if necessary, modify them according to specific needs. The licenses do not discriminate against any category of users, group or person, and they do not prohibit the use of the software in any particular field of application. Furthermore, according to the Open Source definition, the software developed and distributed cannot later be resold or appropriated by anyone. Open Source software is thus associated with the freedom that it concedes and not with the fact that it is free of charge, as a superficial analysis of the phenomenon might lead one to believe.
Open Source products are made within a community composed of a heterogeneous group of players or agents who interact but are driven by different interests and motivations (Bonnacorsi & Rossi, 2002; Lerner & Tirole, 2001; Tzouris, 2002; Weber, 2000). Some authors refer to the Open Source community using the metaphor of a bazaar, since it expresses the idea of the frenzy and chaos with which the activities in the community are carried out (Raymond, 1998). The Open Source community can also be seen as an immense “magic cauldron” of ideas to which volunteers contribute on a continuous basis (Raymond, 1999a). Anyone can draw from this cauldron to suit their needs without having to contribute money or knowledge.
It seems inconceivable that this type of system is able to continue to maintain itself. What seems even more improbable is that its apparent disorganization can produce concrete results. Nonetheless, the products developed in recent years (e.g., Linux, Apache) have made it possible to show that organizational criteria actually do exist within this community.
By observing numerous Open Source projects, it is possible to identify the following five categories of agents involved in the community.
USER
This category is made up of all the people who use Open Source products but do not directly participate in their development because they do not have the ability, time, and/or resources to do so. Users are of fundamental importance, as they make it possible to carry out the timely and exhaustive process of observing and testing the product, and thus the code, which in turn produces feedback for the software developers.
PROSUMER (PRODUCER AND CONSUMER)
Prosumers are the software developers who actively participate in product development not only to meet their own needs but for the pure pleasure of developing products, and, in most cases, with the hope of improving their own professional prospects.
This group is the nucleus of Open Source code development. It is generally made up of people who come from different social classes and use their free time to work on the development of a code. They might be students or software developers/professionals with very different cultural backgrounds and professional needs.
LEADER TEAMS
This category is made up of software developers and is a sort of élite group chosen by the community based on merit. This group of people is given the authority and responsibility for managing development projects.
A leader team is made up of a tight circle of prosumers who have participated in the definition and production of Open Source products from the beginning.
Leaders dedicate much of their time to planning, managing, and checking the product development process and, therefore, often do not participate in programming. They have the important task of coordinating the development community and are responsible for helping integrate the contributions and feedback from the community. The leader team is, thus, a point of reference for all of the agents, companies, and institutions involved and interested in Open Source software.
COMPANIES
This category is made up of the companies that are interested in the Open Source community and its products. They interact with the Open Source community by using software and financing, and sometimes participating in, the development of software. Therefore, they either influence the development process and evolution of products or simply observe the community in order to improve their own organizational structure and business.
INSTITUTIONS
Institutions are nonprofit organizations and public bodies interested in using, and thus diffusing, Open Source products. Many public bodies, above all universities, have created the cultural environment in which many Open Source products have been developed. Some important products, such as Linux, were created thanks to the technical, and sometimes financial, support of universities. Recently, public bodies have also shown interest in the Open Source community and its products by carrying out studies and sometimes promoting the use of Open Source products in their own structures.
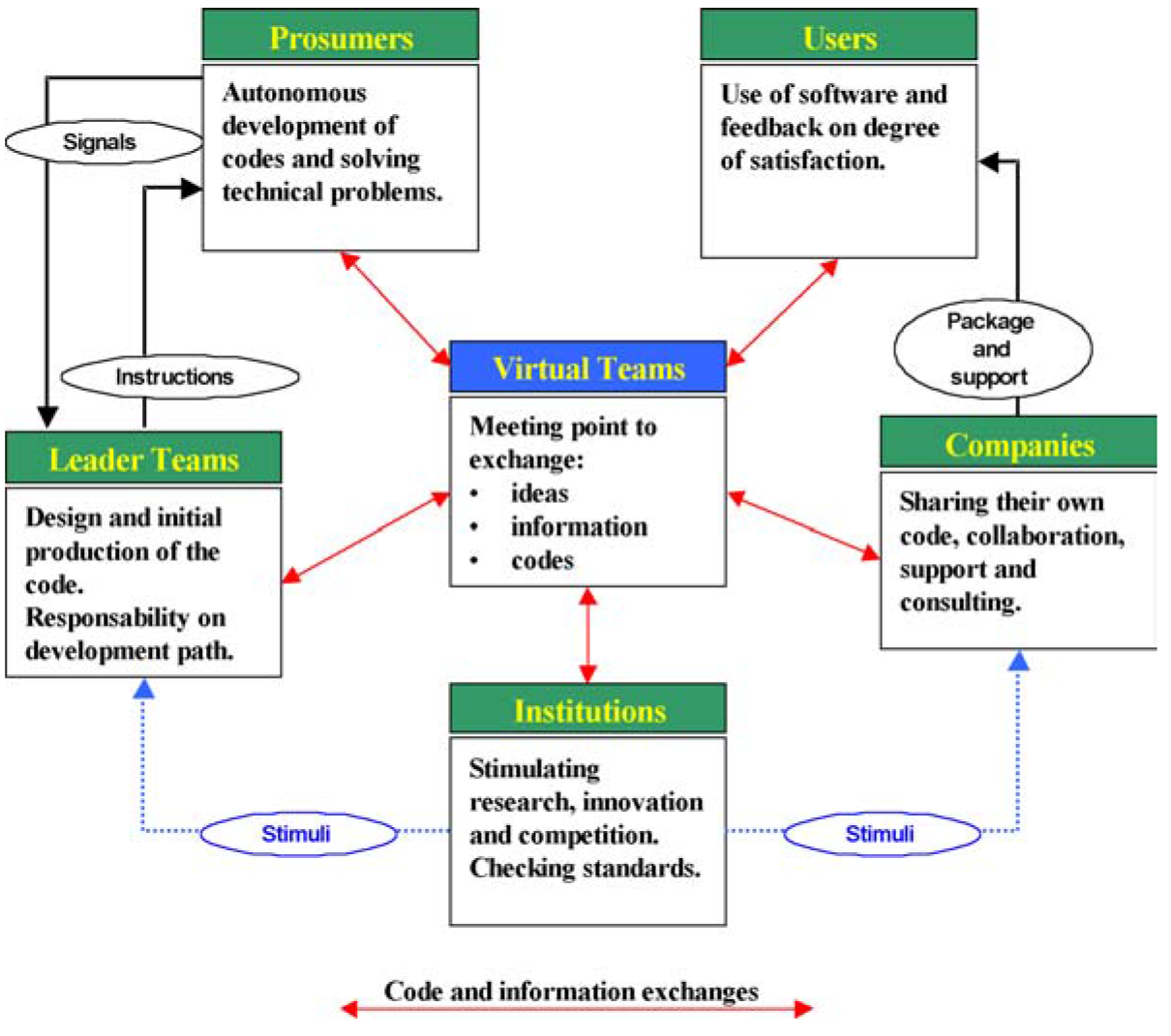
Figure 1 Structure of an Open Source community
The community of agents meets online and creates a dynamic virtual team; that is, a team characterized by the continuous coming and going of agents belonging to the various categories mentioned above. A virtual team is created by agents who contact each other via virtual meetings such as forums and mailing lists. These meeting points make it possible to diffuse concepts, ideas, and strategies to the whole community and at the same time avoid dispersing or slowing down the flow of information and decisions.
Figure 1 shows the five categories of agents who make up the Open Source community and the relationships that exist between them.
CHARACTERISTICS OF THE ORGANIZATION AND PROCESSES OF OPEN SOURCE
Open Source products are, as has been explained above, the result of the collaboration, within a virtual community, of independent and heterogeneous players driven by different interests and motivations (Bonaccorsi & Rossi, 2002; Feller & Fitzgerald, 2002; Lerner & Tirole, 2001; Muffatto & Faldani, 2003; Tzouris, 2002; Weber, 2000). One might expect such a community to become an uncontrollable system. In fact, in order to avoid the generation of negative phenomena, the community has defined its own rules of behavior and functioning that guarantee quality results, stability, and continuity over time. The main characteristics defining how the community works deal with the organizational structure and development process (Bonaccorsi & Rossi, 2002; Dafermos, 2001). This analysis will focus on open participation and bottom-up organization (organizational structure) and the speed of development and parallelism of the process (development process).
Figure 2 overleaf summarizes these four main characteristics and the relationships that exist between them. As can be seen from the figure, open participation leads to both the other characteristic of organization—that is, bottom-up organization—and the two main characteristics of the development process—that is, the speed of development and parallel development.
Open participation generates decentralized decision-making power and thus the absence of rigid top-down planning. Projects can therefore be more flexible and have greater freedom to evolve. However, this can also lead to code forking, which is a situation that occurs when independent development paths of a code fork off in different directions (Raymond, 1999b). When code forking happens, the community tends to lose interest in the project. This loss of interest may provoke a gradual yet unstoppable distancing of software developers from the project, which is consequently destined to die. The end result could be the implosion of the community itself.
However, decentralized decision-making power does not mean a total lack of organization. In fact, in the Open Source community each project has a team of leaders whose appropriate management of consensus can limit the negative effects of code forking. The leader team is responsible for the development process and must answer to the whole community and all of the users. This small group of agents is also responsible for guaranteeing the compatibility and integration of the contributions. The power of the leader team does not come from a privileged position or from property rights; rather, the position they occupy is legitimized by the development community itself. Their power is recognized according to the credibility and trust the community places in them. This credibility allows the leaders to exercise the power of dissuasion when there are actions that could lead to code forking.
Figure 2 Characteristics of the organization and development process of the Open Source community
Another positive effect of open participation is the possibility it offers to explore different alternatives and keep strategies flexible. However, flexibility makes it difficult to define precise deadlines for development. This uncertainty could lead to a lack of incentives for software developers and limit their commitment to a project, which could, in turn, slow down the development process. However, the software developers try to avoid these problems by producing many frequent releases of the code in order to motivate themselves and others to contribute actively (Jørgensen, 2001).
The speed of development and frequency of releases create a continuous evolution of the products. At the same time, the codes are relatively instable due to their incessant evolution, making it difficult for users to use the products. Even though on the one hand continuous modifications and new releases help keep the products technologically advanced and innovative, on the other hand this could discourage their being used. Innovation does not always guarantee product reliability and stability; at least not until products have undergone sufficient checks, trials, and modifications. In other words, users are not willing or inclined to use recent versions of a product whose quality the community is still not able to guarantee.
In order to reach a satisfactory compromise between the exploration of new solutions and the exploitation of existing ones, a project's development process is usually split into two development paths. The first one, called the stable path, is made up of products that have been proved to be stable and whose compatibility over time with future versions of the same products has been guaranteed. The second one, called the development path, is made up of the most recent versions of products that have not been sufficiently checked and tested, and are therefore still merely the fruit of research and innovation. The subdivision of development into two paths, product exploitation and exploration, makes it possible to improve the distribution of responsibilities and the organization of activities, while maintaining a relatively fast speed of development and high degree of innovation.
The last effect of open participation is the parallel development of projects. When there are many different possible solutions, it is not always easy immediately to identify the best one. Parallelism allows many different players to explore different alternatives contemporaneously without forcing them to follow one particular evolutionary path. However, a disadvantage of parallelism is that any overlap and/or interference between the various contributions could lead to incompatability, thus making it difficult to manage development projects.
When software is produced in the traditional way, excessive parallelism is considered to be a waste of resources and a factor that increases the complexity of the development process. Brooks' Law states that as the number of software developers increases, there is a proportional increase in the amount of code produced, but also an increase in the complexity of the project proportional to the square of the number of software developers (Brooks, 1975). This complexity leads to higher communication and management costs and a greater probability of making errors. In order to avoid these problems, the Open Source model suggests subdividing relatively large products into more simple modules. In this way, resources are used more efficiently and any interferences between single contributions are more easily solved.
The leader team is responsible for the modularity of Open Source products. The leaders plan products and the interface protocols to be used for communication between the various modules. Modularity also means that additions, modifications, and imperfections present in one module do not have negative effects on the whole code, but rather are limited to that one module.
We will now interpret these characteristics of the Open Source community in the context of complex adaptive systems theory, but before doing so will briefly define some key aspects of this theory.
COMPLEX ADAPTIVE SYSTEMS
A system is made up of a heterogenous group of interrelated elements. Some of these elements can be defined as agents. Agents can interact with each other and with their environment. Each agent has its own strategy. A strategy is the way in which an agent pursues its own goals, interacts with the other agents, and reacts to stimuli from the environment. Strategies are selected using certain measures of success (Axelrod, 1984; Axelrod & Cohen, 1999). An efficient strategy tends to be followed by many agents. This leads to a population of agents; that is, a group of agents that imitate one another's way of acting. The evolution of a system heads in a given direction according to the strategy identified by its population of agents.
A system is said to be complex and adaptive when the agents have the possibility of continually adapting their actions in response to the environment and the behavior of the other agents. For this reason, the possibility of transferring information from one agent to another, which depends on connectivity, is particularly important in complex systems. The high level of connectivity that characterizes complex adaptive systems allows for the creation of a dynamic network of agents that are constantly communicating and interacting (Coleman, 1999; Kelly, 1994; Lissack, 1999; McKelvey, 1999; McKelvey & Maguire, 1999; Waldrop, 1992).
The interaction between the agents leads the system to take on some emergent properties that characterize the system but are not present in any single agent. The word “emergent” means that the properties of a system “emerge” from the interaction between agents and are not dictated by a central authority. The emergent properties can lead a system toward new evolutions that cannot be foreseen. Therefore, a structured and predefined organizational control system cannot work. Nonetheless, the fact that the evolution of a complex system is difficult to foresee does not mean that there is no organization. In fact, a complex adaptive system is characterized by self-organization.
Three fundamental processes can be identified in complex adaptive systems: variation, interaction, and selection (Axelrod & Cohen, 1999).
VARIATION
In any system, at any time, it is possible to find a certain degree of variety, which is defined as the set of differences and alternatives that characterize both the agents and their strategies. Variety is the result of a process of variation; that is, changes in the set of alternatives. Variation determines the number of possible alternatives in a system.
INTERACTION
Interaction is defined by the ties that exist between agents and the ways in which the agents and their strategies influence each other. Interactions are neither random nor completely predictable. The quantity and quality of the interactions determine the dynamics of the system.
SELECTION
Selection is the process of choosing and diffusing or eliminating properties that characterize agents and their strategies. Therefore, it deals with the ability a system has developed to identify which agents and strategies are to be chosen and thus diffused, and which, on the other hand, are to be eliminated. Consequently, selection determines the evolution of a system.
All of these characteristics of complex adaptive systems can be found in the Open Source community.
OPEN SOURCE AS A COMPLEX ADAPTIVE SYSTEM
The Open Source community can be considered an example of a complex adaptive system. It is made up of a population of heterogenous players, each having its own role and self-defined strategies (Axelrod & Cohen, 1999; Kuwabara, 2000). In the Open Source community, the various roles are not rigidly assigned by a higher authority; on the contrary, each player has the freedom to act and interact with the other players in the system. Therefore, the players in the Open Source community have the characteristics to be defined as agents. They can influence the system by interacting with the rest of the community and are able to use their experience and memory to model their behavior in the present.
The definition of agent proposed by complex adaptive systems theory makes it possible to include users in this category as well. In fact, users can stimulate the system—that is, the community—through explicit and implicit feedback. Users are an integral part of the Open Source system since they participate in the processes of variation, interaction, and selection and, by doing so, can influence the evolution of the system.
According to Axelrod and Cohen, the concept of complex adaptive systems can be most easily related to problems that are long term or diffused, require continuous innovation, need a great deal of feedback in a short period of time, or have a low risk of catastrophe. All of these characteristics can be found in Open Source products.
Long-term or diffused applications offer many opportunities for agents to come together. This leads to a critical mass that can activate significant processes of variation and interaction. In the case of software, examples of this type of application are operating systems, network platforms, web servers, programming languages, and all of the components and protocols that have created the standards of the Internet. Some Open Source products are part of this category of long-term applications. They are usually platforms or common standards; for example, Linux, Apache, and PHP.
In the case of applications that require continuous innovation—that is, those in particularly dynamic industries—there is a significant need to explore new solutions. This is the case for software applications related to the Internet, such as web servers, protocols, browsers, and so on. Since Open Source products are technologically advanced and innovative, they stimulate the creativity of the community and the continuous exploration of alternatives.
As far as applications that require a great deal of feedback over a short period of time are concerned, significant advantages can be gained from the interaction between the agents in a development community. In the Open Source community, the users are considered to be the main source of inspiration for and evaluation of the quality of the products. The fact that products are available at a low cost makes it possible to obtain a significant quantity of information and to have the software undergo an extensive process of observation and checking based on daily use. The fact that the code is open and available to all makes it easier to carry out better measurements of product performance. This in turn gives agents a precise series of parameters that they can use to evaluate product performance objectively and, consequently, base their choices on.
Applications with a low risk of catastrophe are those for which the efforts committed to exploring alternatives should not put the survival of the entire system at risk. A system that manages to do this is dynamic and at the same time stable and, therefore, not at risk of implosion. The modular structure of Open Source products limits the effects that each activity can have on the entire product and makes it possible to avoid the diffusion of any imperfections. Furthermore, the failure of one or more exploratory actions does not lead to the failure of the entire system, which nevertheless continues to survive since there are other players involved in the development process. In fact, in Open Source nobody has total control over or responsibility for products and each activity is usually shared by a group of autonomous agents. Should any agent decide to stop carrying out its activities, it can easily and quickly be substituted regardless of the position that it occupied.
Axelrod and Cohen consider Open Source mainly as an example of the variation mechanism, since it very much exploits the advantages gained from conserving diversity within a system. One of the main dangers for a complex system is the extinction of a type of agent or strategy that reduces a system's diversity. Since the creation of a type requires resources and effort, its premature extinction should be avoided. A type that is not very successful in the present might have characteristics that could prove to be very important in the future. The Open Source community manages to conserve diversity by keeping track of the whole evolutionary process in order to be able easily to find anything that might be needed.
It is also possible to identify the interaction and selection mechanisms in the Open Source community. Above all, it is possible to understand how the close relationship that exists between these mechanisms allows the Open Source community efficiently and effectively to exploit its own complexity.
Axelrod and Cohen identify a sequence in the mechanisms of variation, interaction, and selection. They consider variation to be a premise for the activation of different forms of interaction, which, in turn, produce effects of selection within a system. However, it is possible to hypothesize that there are other sequences of variation, interaction, and selection in the characteristics of the Open Source organization and development process mentioned above; that is, open participation, bottom-up organization, speed of development, and parallel development. The benefit of each characteristic can be interpreted as one of the mechanisms, but it is also possible to identify a negative effect, which can be interpreted as another mechanism, and the actions taken to solve the problem can be interpreted as the remaining mechanism (Figure 3).
Figure 3 Characteristics of a complex adaptive system in the Open Source community
The advantage of open participation—that is, the free exploration of alternatives and flexibility of strategies—can be interpreted in terms of variation. In the Open Source community, however, agents tend to work on development for long periods of time without making their solutions available. In this way, they do not stimulate the other agents in the community. This can be interpreted as a phenomenon of premature and highly subjective selection. In other words, this selection remains within the subjective evaluation of individual agents and does not benefit from the contribution of many different agents in terms of peer review. Furthermore, the agents are not solicited enough to offer new contributions to the development process. The result of this excess is that the exploration process slows down, limiting the variety in the system. One solution to this problem is to increase the frequency with which software is released. Basically, the community makes a release each time there is a new feature, even if it is relatively insignificant, in order to motivate and involve the agents in the community. This action, seen from the point of view of complexity theory, has the effect of increasing the interaction between agents.
Another characteristic of the organizational structure of the Open Source community is decentralized decision-making power; that is, the implementation of a bottom-up organization. As has often been noted, the advantage of decentralized power is an increase in the flow of information within an organization. If the organization of the Open Source community is interpreted as a complex system, this effect can be interpreted as an increase in the possibilities for interaction between the agents in the system. This increase in horizontal interaction can, however, lead to a negative effect, code forking. Code forking can be interpreted as a negative aspect of variation that can damage the development of Open Source projects. The solution, in this case, is to create elements of organizational structure in the Open Source community as well; that is, leader teams. The leaders' efforts to maintain consensus help the community not to lose its connectivity, as is the case with code forking where agents work on the same objects without exploiting the positive effects of interaction. In this way, leaders carry out selection by deciding what direction product evolution will take.
As we have seen, the Open Source development process is characterized by frequent releases in order to motivate the community to participate. The advantage of frequent releases is the continuous evolution of the products; that is, their dynamic variation, which leads to significant variation in the system itself. Nonetheless, if new versions of a product are released too rapidly, there could be an excess of exploration, to the disadvantage of the exploitation of the results already obtained. This effect could lead to a lack of focus and scarce and ineffective interaction between agents. The Open Source community attempts to avoid this problem by separating the development process into a dual path. In the stable path, which corresponds to the exploitation of results already obtained, variation is very slow. In the development path, which corresponds to the exploration of new alternatives, there is a great deal of variation in the system. The two different development paths are managed through a process of selection, in which contributions must be separated into two groups: on the stable path there are those that only need to be consolidated, while on the development path there are those that need to be developed further.
Finally, there is the parallel development of products. The advantage of this is the possibility of exploring a greater number of different alternatives at the same time. In other words, parallelism has the positive effect of variation regarding both the type of agents involved in the system and the strategies they pursue. Nonetheless, the parallel development of one product can also lead to excessive complexity and even incompatibility between components and alternative product solutions. In fact, one single modification can have a significant impact on other parts of the product and the effect of the impact is unpredictable. This could be seen as a negative effect of the interaction between the elements in the system. The solution to the possible negative consequences is parallel development organized according to modular product planning. A precise definition of the modularity forces agents to make a selection of the objects on which they want to work, and at the same time limits possible interference with the activities of other agents.
In conclusion, in each of the functioning characteristics of the Open Source community it is possible to highlight the three fundamental mechanisms of complex adaptive systems. Whereas in the variation-interaction-selection sequence all the mechanisms have positive effects on the system, we have considered the possibility of other sequences characterized by the presence of a mechanism having negative effects on the system. Finally, we have shown that the solution to the problems caused by the negative effects of one of the mechanisms can be interpreted as the effect of another one.
IMPLICATIONS
The observations made in this article can lead us to reflect on how the interpretation of the phenomena analyzed here can be extended within this context as well as to other contexts. Similar contexts could be those dealing with knowledge products whose characteristics are similar to those of software. This analysis could therefore also be extended to involve the processes of scientific research in general, and those of highly innovative fields such as bioinformatics or pharmaceutical research in particular. Furthermore, since Open Source tends to diffuse and impose itself as a standard, it would be worthwhile studying the problem of strategies for setting and diffusing technological standards. Finally, since the concept of complexity can be used to interpret social characteristics as well, the complex adaptive systems theory would certainly be suitable for interpreting networks and clusters. Given the flexibility of the complex adaptive systems theory, it would certainly be worth dedicating significant analysis to the applicability of this theory to various contexts.
References
Axelrod, R. (1984) The Evolution of Cooperation, New York: Basic Books.
Axelrod, R. & Cohen, M. D. (1999) Harnessing Complexity: Organizational Implications of a Scientific Frontier, New York: Free Press.
Bonaccorsi, A. & Rossi, C. (2002) Why Open Source Software Can Succeed, Pisa, Italy: Laboratory of Economy and Management, Sant'Anna School of Advanced Study.
Brooks, F (1975) The Mythical Man Month: Essays on Software Engineering, London: Addison Wesley.
Coleman, J. H., Jr. (1999) “What enables self-organizing behavior in businesses,” Emergence, 1(1): 33-48.
Dafermos, G. N. (2001) “Management and virtual decentralised networks: The Linux project,” First Monday, 6(11).
Di Bona, C., Ockman, S., & Stone, M. (1999) Opensources: Voices from the Opensource Revolution, Sebastopol, CA: O'Reilly & Associates.
Feller, J. & Fitzgerald, B. (2002) Understanding Opensource Software Development, London: Addison Wesley.
Free Software Foundation (2002), February, http://www.fsf.org.
Jørgensen, N. (2001) “Putting it all in the trunk: Incremental software development in the FreeBSD open source project,” Information Systems Journal, 11: 321-36.
Kauffman, S. A. (1995) At Home in the Universe: The Search for Laws of Self-Organization and Complexity, Oxford, UK: Oxford University Press.
Kelly, K. (1994) Out of Control: The New Biology of Machines, Social Systems, and the Economic World, Reading, MA: Addison Wesley.
Kuwabara, K. (2000) “Linux: A bazaar at the edge of chaos,” First Monday, 5(3).
Lerner, J. & Tirole, J. (2001) “Some simple economics of Open Source,” Journal of Industrial Economics, 50: 197-234.
Lissack, M. R. (1999) “Complexity: The science, its vocabulary, and its relation to organizations,” Emergence, 1(1): 110-26.
McKelvey, B. (1999) “Complexity theory in organization science: Seizing the promise or becoming a fad?,” Emergence, 1(1): 5-32.
McKelvey, B. & Maguire, S. (1999) “Complexity and management: Moving from fad to firm foundations,” Emergence, 1(2): 5-49.
Muffatto, M. & Faldani M. (2003) “Realta e prospettive dell'Open Source,'” Economia & Management, 3.
Open Source Initiative (2002), 24 February, http://www.opensource.org.
Raymond, E. S. (1998) “The cathedral and the bazaar,” First Monday, 3(3).
Raymond, E. S. (1999a) “The magic cauldron,” http://www.catb.org/~esr/writings/magiccauldron/magic-cauldron.html.
Raymond, E. S. (1999b) The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary, Peking/Cambridge, MA/Farnham, UK: O'Reilly & Associates.
Tzouris, M. (2002) Software Freedom, Open Software and the Participant's Motivation: A Multidisciplinary Study, London: London School of Economics and Political Science.
Waldrop, M. M. (1992) Complexity: The Emerging Science at the Edge of Order and Chaos, New York: Simon & Schuster.
Weber, S. (2000) “The political economy of Open Source software,” BRIE working paper 140, Berkeley, CA: E-conomy Project.